Rails で JSON Schema バリデーションする gem を作った
諸事情により今頃 Rails に再入門中なのですが、Rails Plugin の練習も兼ねて JSON Schema でパラメータをバリデーションをする gem を作ってみました。
https://github.com/kotas/json_schema_rails
https://rubygems.org/gems/json_schema_rails
今運用中のサービス(非 Rails)では JSON Schema でのバリデーションを自作していましたが、Rails4 でクライアントサイドバリデーションをやろうとすると、今のところデファクトな選択肢がないっぽく(Rails3 までは client_side_validations がメジャーだったようですが開発終了っぽいし)、リアルタイムバリデーションどうすっか、となって移植してみたのです。
こんな感じの YAML を app/schemas/posts/create.yml に書いて
--- "$schema": "http://json-schema.org/draft-04/schema#" title: Create Post type: object required: - post properties: post: type: object additionalProperties: false required: - title - body properties: title: type: string body: type: string
Controller 側で
class PostsController < ApplicationController # Validate requests for all actions in this controller validate_schema def create end def update end end
みたいな感じで書くと自動的にパラメータがバリデーションされます。
モデル側に書くのも考えたのですが、Rails4 からは Strong Parameter で Controller 側にパラメータ検証を移しつつあるっぽいので、いっそこんな感じに。
他にも
などが付属します。
JSON Schema を使うメリットとして、
- バリデートするためのライブラリがどの言語でも大抵すでにある
- JavaScript でもそのまま使えるので、クライアントサイドとサーバサイドで同じバリデーションが DRY に出来る
- 仕様が複雑すぎず、シンプルすぎない
などがあり便利です。
Rails はほぼ初心者な状態なので、何かツッコミあればビシバシどうぞ><
Ruby + Padrino で DDD (1)
長年、仕事では PHPer + JSer + α だったのですが、今年に入って Rubyist に入門しています。
Web アプリを1から作るにあたって、自分の中では DDD が熱かったので、ActiveModel を回避するために Rails 以外の選択肢を模索して、Padrino に行き着きました。
Ruby + Padrino で DDD をやるにあたって、どうやっていったか記録しておこうと思います。いくつかに分けて書く予定。
Padrino のモデル層について
Padrino は、Sinatra に Rails ライクな Helper や Mailer やリロード機構やら、色々便利な皮をかぶせたもので、モデル層は ORM 使ってもいいし、使わなくてもいいよ、みたいなスタンスのフレームワークです。
今回は DDD やりたかったので ORM は使わない事にしました。(※かなり茨の道なので、あまりオススメできません)
ValueObject と Entity
DDD における ValueObject といえば、何かの値を表現するために用いられ、値のみで識別されるオブジェクト。Entity といえば、ライフサイクルを通して一貫した ID を持ち、ID で識別されるオブジェクト。
識別については、素直に == や hash をオーバーライドして、それぞれ attribute を使ったり、id を使ったりしました。
VO の識別に使われる attribute については、attr_reader をオーバーライドして定義された getter を記録するようにしました。
実際に使われてるコードはもっと手を加えてますが、イメージとしてはこんな感じです。
module DDD class Object class << self def attr_reader(*names) attributes.concat(names) super(*names) end def attributes @attributes ||= [] end end end class ValueObject < Object def ==(other) self.class.attributes.all? do |attr| send(attr) == other.send(attr) end end alias_method :eql?, :== def hash self.class.attributes.map { |attr| send(attr) }.hash end end end class Color < DDD::ValueObject attr_reader :r, :g, :b def initialize(r, g, b) @r, @g, @b = r, g, b end end red1 = Color.new(255, 0, 0) red2 = Color.new(255, 0, 0) blue = Color.new(0, 0, 255) p red1 == red2 # true p red1 == blue # false
Entity の ID
ID の一意性をどう担保するか、という問題と、リポジトリ実装の都合上 DB の AUTO_INCREMENT に頼るのは避けたかったので、ID 生成は自前で実装する事にしました。
UUID を使っても良かったんですが、データサイズ的にやはりつらさがあるので、unsigned 64bit int で Twitter の Snowflake を参考に自作してみました。
64bit を分割して
- タイムスタンプ (41ビット): 2014-01-01 00:00:00 +00:00 からの経過ミリ秒数
- シャード番号 (12ビット): サーバープロセスごとに変更する
- シーケンス番号 (11ビット): ID生成の度インクリメントされ、毎ミリ秒ごとリセットされる
という構造の ID を作っています。
外部に ID 生成用サーバーを持たなくてもローカルで何とか出来るため安上がりで済み、毎ミリ秒 2048 個の ID を作成できて、しかもプロセスごとに重複しないため、ユニーク性をそれなりに保証できるなど便利です。
タイムスタンプがミリ秒で 41 ビットと聞くと、一見心許なく感じますが、約70年間は枯渇しません。
((1 << 41) - 1) / 1000 / 60 / 60 / 24 / 365 = 69
Immutability
Ruby で immutable というのは、あんまり見かけないんですが setter 定義を縛る事で一応可能です。
immutable にするメリットは色々あると思いますが、やはり大きいのは気軽に引数で引き渡し回せるようになる事と、テストのしやすさだと思いました。
Entity を immutable にするかは迷ったんですが、ものは試しでやってみる事にしました。
状態を変えたい時のために、以下のようなメソッドを基底クラスに定義していて
def transform(&block) cloned = dup cloned.instance_eval(&block) cloned end
状態の変更は以下のように行えるようにしました。
def pay transform do @paid = true @paid_at = Time.now end end
以下のように更新後のインスタンスが返ってきます。
ticket.paid # false paid_ticket = ticket.pay paid_ticket.paid # true ticket.paid # false
dup するのでややコストがありますが、やはり状態が変わると別インスタンスになるというのは、状態毎に適切な名前を付けられますし、一度作ったインスタンスの状態変化を気にしなくて済むのでありがたいですね。
つづく
(あれ、ここまで Padrino ほとんど関係ないな…)
Docker で Web アプリを運用してみた
Docker してますか!
実は実験的に Docker で Web アプリを数ヶ月運用しており、色々と試行錯誤してきたので、少しずつアウトプットしていきます。
ちなみに Ruby 製のアプリで、AWS の EC2 上で運用している、小〜中規模ぐらいのものです。
2014-06-16 16:00: 追記あり
Docker イメージのビルドについて
Dockerfile を普通に書いてます。
今のところ、2層構造にしていて、
- ベースとなるイメージ
- Ruby
- アプリケーションサーバー (Puma)
- アプリケーションのソース (git clone)
- bundle install
- デプロイされるイメージ (ベースイメージを元に作る)
- git pull してソース更新
- bundle install し直してベースにない gem を入れる
- asset の precompile
という感じでやってます。
ベースイメージは1日1回、デプロイイメージは master への push を trigger にビルドしていて、ビルドは Jenkins でシェルスクリプトでゴリゴリやってます。
Jenkins のビルドID (日時) をタグとしてレジストリに push するようにしています。
レジストリについて
プライベートレジストリを自前でホストしてもいいんですが、運用面倒なので quay.io を使ってました。
quay.io は、UI が便利だったり、ボット用のトークンが簡単に払い出せたりできて便利です。
しかし、Docker Hub も発表されましたし、料金も安いので公式リポジトリ (index.docker.io) に移行中です。
(機能的には、push して pull するだけなら、どちらも大差ないので…)
イメージをサービスごとに細かく分割していくと、あっという間にレジストリ数の上限に引っかかるのが悩みどころ。妥協して supervisord などで1つにまとめていくのもアリだと思います。
ログ収集について
コンテナは使い捨てが基本なので、ログはどこかに退避させる必要があります。
docker run のオプションで -v や --volumes-from を使うとホスト側ディレクトリをマウントできるので、そちら経由でホスト側に退避させる事もできるのですが、ホスト側も使い捨てたいので、fluentd を使っています。
構成はベーシックな fluentd + ElasticSearch + kibana で、それぞれコンテナ立てて動かしています。(kibana は nginx をサーバーに)
ホットデプロイについて
一番悩んだのがアプリのデプロイ。
実行については docker pull して docker run でいいとして、ダウンタイム無しで切り替えるのはどうしようか、という感じです。
どうせなら Blue-Green Deployment もしたいので、いくつか方法を試してみました。
- Elastic Load Balancer で EC2 インスタンス抜き差し
- Elastic Beanstalk の Docker デプロイを利用
- 最近 Beanstalk で Docker デプロイが出来るようになったので、試してみた
- Beanstalk では DNS の CNAME レコード書き換えで Blue-Green ぽい事ができる
- 利点
- デプロイが簡単 (レジストリに push 済みなら JSON を送るだけでデプロイできる)
- ツールがある: eb_deployer
- 欠点
- DNS 書き換えでの切り替えなのでクライアントのキャッシュ依存
- http://example.com/ のようなサブドメインの無い URL で運用できない(Route53 の Alias が Beanstalk の CNAME レコードをサポートしていないため ELB が使えない)
- デプロイに時間が掛かる:Beanstalk のデプロイが EC2 インスタンスを1から立ち上げるため
で、両方とも結局 EC2 インスタンスの立ち上げが遅いという結論にいたり、どうせ docker 使っていてコンテナの immutability は確保できるので、ホストは使い回す事にしました。
nginx + mruby で backend 書き換え
良い方法はないかなーとググっていたところ、Docker, Mesos, Sensu等を利用したBlue-Green Deploymentの仕組み を見つけて パク 参考にさせて頂く事にしました。
結局のところ、リバースプロキシである nginx の後ろのアプリだけ切り替えられればいいので、nginx の設定を動的に書き換える事にしました。(immutable とは一体…うごごご)
せっかくなので、面白そうだった ngx_mruby (組み込み用 Ruby である mruby を nginx で使えるようにする拡張) を使って、アプリと別ポートで設定書き換える API を作り、デプロイ時に叩くようにしました。
server {
listen 8888;
server_name ctrl;
location = /backends {
mruby_content_handler /etc/nginx/mruby/backends.rb;
}
}
BACKEND_CONF = '/etc/nginx/backend.conf' r = Nginx::Request.new if r.method == 'POST' json = r.args.gsub(/%[0-9a-fA-F]{2}/) { |s| s.slice(1..-1).to_i(16).chr } begin backends = JSON.parse(json) rescue ArgumentError => e Nginx.errlogger Nginx::LOG_ERR, "Invalid json received: #{e.message}" Nginx.return Nginx::HTTP_BAD_REQUEST return end conf = "# Generated at #{Time.now}\n" conf << "upstream backend {\n" backends.each { |backend| conf << " server #{backend} fail_timeout=0;\n" } conf << "}\n" File.open(BACKEND_CONF, 'w') { |f| f.write(conf) } Nginx.errlogger Nginx::LOG_INFO, "Updated backend conf to: #{json}" else if File.exist?(BACKEND_CONF) conf = IO.read(BACKEND_CONF) else conf = '' end end r.content_type = 'text/plain' Nginx.echo conf
そして、この API をデプロイ時に叩きます。
# アプリコンテナのプライベート IP 取得 CONTAINER_IP=$(docker inspect -f '{{ .NetworkSettings.IPAddress }}' $APP_CONTAINER_NAME) # API 叩いて backend.conf を書き換え BACKENDS=$(ruby -rjson -ruri -e 'puts URI.encode_www_form_component(ARGV.to_json)' "$CONTAINER_IP:$APP_PORT") curl -X POST 'http://localhost:8888/backends?'$BACKENDS # HUP 送って設定反映 docker kill -s HUP app-nginx
しかし動くんだよなぁ、これが。しかも切り替えは一瞬で済むという…。
これにより、デプロイに掛かる時間はほぼ docker pull 分だけで済むようになりました。
欠点としては、同じ EC2 インスタンスを使い回すのでメンテナンスが必要になる事ですね…
Docker の安定性について
Docker 自体は今のところ安定して稼働できています。
Docker 1.0 もリリースされましたし、まだ気になるところもあるのですが(docker pull 中に Ctrl-C すると docker pull できなくなる事があるとか)、そろそろ実用いけるんじゃないでしょうか。
もうちょっと運用してみたいと思います。
追記: 2014-06-16 16:00
ngx_mruby の開発者である id:matsumoto_r さんに反応していただき、違う構成のエントリも書かれていたのでご紹介がてら、twitter 上でのやりとりを引用します。
Dockerとmrubyで迅速かつ容易にnginxとapacheの柔軟なリバースプロキシ構成を構築する
Docker の --link を使って、コンテナ間接続をして nginx → アプリ を構成する例をご紹介されています。
私も、この構成は試していたのですが、Docker の --link が仕様上、起動時に静的にコンテナ間の接続を決定してしまうため、デプロイ毎に nginx コンテナを再起動する必要があり、ダウンタイムが発生するため、見送った経緯がありました。上記の ELB のインスタンス抜き差しなどインスタンス単位でのダウンタイムを別レイヤで吸収できるのであれば、Docker の本流というべき綺麗な構成にできると思います!
こちらについて、コメントしたところ、twitter 上で反応いただけました。
この構成、デプロイの度に nginx コンテナを再起動する必要があり、ダウンタイムが発生するのが難点であきらめ、設定ファイルの動的書き換えに逃げました… http://t.co/AVyrBwf1vx / “人間とウェブの未来 - …” http://t.co/UrFBzcRuHb
— Kota Saito (@ksaito) 2014, 6月 16@ksaito この構成だと複雑な事をせずに構築できるという利点はありますが、御指摘の問題はありますね。動的書き換えの記事拝見しましたが非常に面白かったです。書き換え対象を例えばRubyスクリプトにしてしまえば、nginxにHUPすることなく振り分ける事も可能です。
— MATSUMOTO, Ryosuke (@matsumotory) 2014, 6月 16@matsumotory ありがとうございます>< できれば設定ファイル書き換え無しで済ませたくて、最初は Userdata を使ってコンテナIPを記録して、動的に mruby で backend を選ぶ、というのを書いたんですが、Userdata が定期的に飛んでしまうっぽく…
— Kota Saito (@ksaito) 2014, 6月 16@ksaito おお、そんな事が…すみません。GCで回収されてしまっているのかもしれませんね。よろしければissueに上げていただければ対応したいと思います。一方で例えば、RedisやVedisからbackendsの情報を引き出すという方法も良いかもしれません。
— MATSUMOTO, Ryosuke (@matsumotory) 2014, 6月 16@matsumotory あまり詳しく検証してなくて申し訳ないのですが nginx のプロセスが定期的に入れ替わってるのかなと、仕様の範囲かと思っていました orz Vedis / Redis も検討したのですが、だったら設定ファイル書き換えいいかな、と落ち着いた感じですw
— Kota Saito (@ksaito) 2014, 6月 16ただ、設定ファイル書き換えにも難点があって、Docker コンテナを再起動すると巻き戻るので、やはり Redis 等の外部ストレージを使うか、Docker の --volume-from や -v で設定ファイルを外部に保持する必要がありそうです。
— Kota Saito (@ksaito) 2014, 6月 16@ksaito そうですね。ブログの構成の利点は、リクエストの度にbackend選択のスクリプトを実行しなくてよくてサーバプロセスとmrubyインタプリタの性能やメモリの問題を意識しなくて良いので、HUPが許されていれば良い選択だと感じました。
— MATSUMOTO, Ryosuke (@matsumotory) 2014, 6月 16@ksaito Userdataのバグ?は今ざっとコード見たところ、最初にuserdataのhashオブジェクトを作る時にオブジェクトをgc_protect()してやれば良いのかな?とも思いましたが、nginxの動作も関係しているのかもしれないので難しいですね…
— MATSUMOTO, Ryosuke (@matsumotory) 2014, 6月 16@matsumotory ありがとうございます。条件を再現できたら issue として挙げさせていただきます!
— Kota Saito (@ksaito) 2014, 6月 16@ksaito あ、誤読かもしれませんが、もしuserdataの使い方がPOSTしてその値をuserdataに入れて...という流れであれば、それだと受けたnginxプロセスのみのuserdataにデータが入るので、他のプロセスには有効ではない、という仕様はあります。
— MATSUMOTO, Ryosuke (@matsumotory) 2014, 6月 16@matsumotory おっと… まさしくその仕様にハマった気がします…orz そりゃあワーカープロセスごとに独立ですよね orz となると、やはり Userdata はキャッシュ用途にだけ使うのが無難ですね…
— Kota Saito (@ksaito) 2014, 6月 16@ksaito まだまだmod_mrubyやngx_mrubyもその周辺のgemも使ってみて気付くことが多いので、ぼくも色々試してみたいと思います。色々やれるようになった分、ハマる所も多そうですね。
— MATSUMOTO, Ryosuke (@matsumotory) 2014, 6月 16相変わらずボケが発動しておりますが orz matsumoto-r さん、ありがとうございました!
ngx_mruby 使うと Ruby であんなことやこんなことができて楽しので、皆使うべきそうすべき!
gulp.js で TypeScript をコンパイルするプラグインを作った
タスクランナー Grunt の対抗馬として今年あたりブームがきそうな gulp.js ですが、TypeScript をコンパイルするプラグインが見当たらなかったので作りました。
https://npmjs.org/package/gulp-tsc
https://github.com/kotas/gulp-tsc
使い方
npm install --save-dev gulp-tsc
して gulpfile.js で以下のように require('gulp-tsc') するだけで使えます。
var gulp = require('gulp');
var typescript = require('gulp-tsc');
gulp.task('compile', function () {
gulp.src(['src/**/*.ts'])
.pipe(typescript())
.pipe(gulp.dest('dest/'));
});
上の例の場合は src 以下の .ts ファイルを、ディレクトリ構造を維持したまま .js ファイルに変換して dest 下に保存します。
1ファイルにまとめたい場合は out オプションでファイル名を指定するだけです。
gulp.task('compile', function () {
gulp.src(['src/**/*.ts'])
.pipe(typescript({ out: 'unified.js' }))
.pipe(gulp.dest('dest/'));
});
上の例の場合は src 以下の .ts ファイルを依存順で結合して、dest/unified.js として保存します。
TypeScript のバージョン
Grunt のプラグインでもありがちなのですが、コンパイルに使う tsc コマンドがプラグインに同梱されている場合に、TypeScript のバージョンがそのプラグイン同梱版に固定されてしまう、という問題があります。
例えば、少し古いバージョンの TypeScript でコンパイルしたいのに、プラグインをバージョンアップしたら TypeScript のバージョンまで更新されてしまって困る、という話がありました。
gulp-tsc では、この問題を回避するためコンパイルに使う tsc コマンドを以下の順番で検索するようになっています。
カレントディレクトリ/node_modules/typescript/bin/tsc- シェルの PATH での
tsc(which tscで見つかるもの) - gulp-tsc に同梱されている TypeScript の
tsc(バージョンは gulp-tsc に依存)
つまり、プロジェクトの package.json に使いたいバージョンの typescript モジュールを devDependencies (または dependencies) で指定しておくことで、自由にバージョンを選択できるようにしました。
余談: gulp.js プラグインのテストについて
余談なのですが、gulp.js プラグインのテストをするにあたって、「ちゃんとファイルが生成されているのか」を知りたい時があります。
この gulp-tsc でも、コンパイル作業が外部コマンドに依存しているため、ファイルが想定したパスで正しく生成されているかを検証する必要がありました。
で、それを検証するための gulp.js プラグインも作りました。
https://github.com/kotas/gulp-expect-file
これを使うと、pipe() を通してファイルが正しく生成されているか、内容が正しいか、簡単に検証する事ができます。
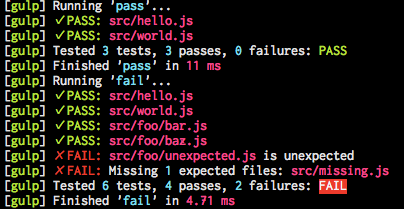
gulp-tsc でも、これを使って実際に gulp を通して TypeScript をコンパイルするテストを作っています。
https://github.com/kotas/gulp-tsc/blob/master/test-e2e/gulpfile.js
おわりに
gulp.js で TypeScript をコンパイルする gulp-tsc を紹介しました。
いつでも pull request や issue 等お待ちしています!
Enjoy!
TypeScript でユーザースクリプトを書いた
TypeScript で NicoNicoFavlist というユーザースクリプトを書いたので、その時の備忘録などを記しておきます。
https://github.com/kotas/niconico-favlist
ユーザースクリプトを TypeScript で書く
ユーザースクリプトを動かすためのブラウザ拡張の多くは、オリジナルの先駆者である Greasemonkey と互換性のある API セット を提供しています。
TypeScript で上記の API を扱うのであれば、その定義ファイル (.d.ts) が必要となるのですが、見当たらなかったので自分で作りました。
https://github.com/borisyankov/DefinitelyTyped/blob/master/greasemonkey/greasemonkey.d.ts
(半) 公式リポジトリに pull req も出しておいたらマージされてました。やったね。
ビルドフロー
書いた TypeScript を最終的にユーザースクリプトにビルドする必要があるので、自動化のために grunt を導入しています。
TypeScript -> JS
TypeScript -> JS 変換は grunt-typescript という grunt プラグインがありますので、以下のような感じで設定書いておけば動きます。簡単ですね。
typescript:
userscript:
src: ['src/userscript/main.ts']
dest: 'compiled/userscript.js'
options:
comments: false
src に指定したファイルが中で <reference> で参照しているファイルも勝手にコンパイル対象となります。src/**/*.js のように指定してもいいんですが、こうすると必要ないファイルの結合を防ぐ事ができます。
dest を .js 付きのファイル名にしておけば、1ファイルに結合してくれます。(もちろんファイル構造を維持したまま .ts -> .js の map もできます)
HTML / CSS の埋め込み
ユーザースクリプトでは、最終的に1つの JavaScript ファイルにまとめる必要があるため、HTML や CSS などの静的ファイル類も JS ファイルに埋め込む事にしました。
Handlebars などのテンプレートエンジンを使っても良かったのですが、テンプレートとしてではなく静的ファイルとしてで十分だったので、超簡単なものを自作しました。
色々考えた結果、ファイル結合をしてくれる grunt-contrib-concat を使う事にしました。設定は以下のように書いています。
concat:
resources:
files:
'compiled/resource.js': ['resources/*.html', 'resources/*.css']
options:
banner: "var Resource = { html: {}, css: {} };\n"
process: (content, path) =>
name = path.replace(/^.+\/|\..+$/g, '')
content = JSON.stringify(content.toString().replace(/^\s+|\s+$/g, '').replace(/\s*\n\s*/g, "\n"))
if /\.css$/.test(path)
"Resource.css['#{name}'] = #{content};"
else
"Resource.html['#{name}'] = #{content};"
options.banner は結合後のファイルのヘッダーとして付与される文字列です。
options.process は結合されるファイルそれぞれについて、ファイルの内容とパスを引数にして呼び出され、return した文字列が結合される内容として使われます。
上記を実行すると、resources/ 以下の html と css が compiled/resource.js に、以下のような形で出力されます。
var Resource = { html: {}, css: {} };
Resource.html['hello'] = "<div class=\"hello\">\nHello\n</div>";
Resource.html['world'] = "<div class=\"world\">\nworld!\n</div>";
Resource.css['hello'] = ".hello {\ncolor: red;\n}";
Resource.css['world'] = ".world {\ncolor: red;\n}";
あとは、これを以下のように読み込めるようにしました。
var $hello: JQuery = Resource.load('hello');
var $world: JQuery = Resource.load('world');
TypeScript 側のコードは以下です。ポイントは export declare var html のように declare で宣言のみしている事で、これにより上記で作られる JS ファイルでの設定を上書きしないようにしています。
ユーザースクリプト用の加工
ユーザースクリプトとして動かすには、以下の点に気を付ける必要があります。
専用のヘッダーは、そのまま TypeScript ファイルに書いておいてもいいのですが、「ファイルの先頭」である必要があったり、バージョン情報など package.json に書いてある情報と重複したりするので、テンプレートから動的に生成して、コンパイル済み JS ファイルに grunt でくっつける事にしました。
また、グローバル名前空間の汚染については、スクリプト全体を (function() { })() みたいな即時関数で囲えばいいんですが、あいにく TypeScript 単体では出来ないので、これも grunt でやる事にしました。
以下のようなテンプレートを作っておき
etc/userscript/header.txt
// ==UserScript== // @name <%= pkg.name %> // @version <%= pkg.version %> // @author <%= pkg.author %> // @copyright <%= pkg.copyright %> // @description <%= pkg.description %> // @namespace http://example.com/ // @include http://example.com/ // ==/UserScript==
etc/userscript/intro.txt
(function () {
etc/userscript/outro.txt
})();
同じく grunt-contrib-concat の設定を書き足します。
concat:
userscript:
files:
'dist/niconicofavlist.user.js': [
'etc/userscript/intro.txt'
'compiled/resource.js'
'compiled/userscript.js'
'etc/userscript/outro.txt'
]
'dist/niconicofavlist.meta.js': []
options:
banner: grunt.file.read 'etc/userscript/header.txt'
options.banner に指定する事で、自動的に grunt.template で処理されるので、テンプレート内の <%= pkg.version %> などは package.json に書いておいた情報がそのまま埋め込まれます。
ついでに、.meta.js というヘッダーのみが含まれるファイルを生成しています。この URL を @updateURL としてヘッダーに書いておくと、@version を見てアップデートを確認してくれます。
終わりに
TypeScript は便利なのでみんな使えばいいと思います><
Node 学園祭では存在感が薄くて残念でしたがw
「こわくない Git」というスライドを発表しました
社内向けに「こわくない Git」というタイトルのスライドを作って発表しました。
対象者は「マージがなんとなく怖い」「エラーが怖い」「リベース使うなって言われて怖い」と、Git が怖いと思っている人です!
こわくない Git from Kota Saito
発表中に出た質問など
補足も兼ねて、上のスライドを発表した際に出た質疑応答などをここに書いておきます。
- Q: 常に Non Fast-Forward (--no-ff) でいいのでは、と思えるけど git merge がデフォルトだと Fast-Foward or Non Fast-Forward (--ff) なのはなぜ?
- A1: Non Fast-Forward だと、確かにメリットが多いのですが、1点だけデメリットがあります。特に差分が無い状態で git merge --no-ff すると、空のマージコミットが作られてしまうのです。この挙動が気持ち悪いという人も多いです。
- A2: 都合上、Fast-Forward の悪い点ばかりフィーチャーしてしまいましたが、ブランチを進めるだけでマージと同じ結果が得られる、というのはエレガントだと思いますし、コミットグラフを持つ「git らしい」と思います。
- A3: ベストプラクティスとしては「--no-ff」を付けた方が運用はしやすくなる、という感じですが、状況やチームポリシーに応じて柔軟に!
- Q: Non Fast-Forward でのマージコミットは勝手にコミットされるの?
- A1: はい。git merge --no-ff topic を実行すると、勝手にマージコミットが作られて、そのコミットメッセージの入力画面に移ります。(-m でコミットメッセージを引数で指定すると、コミットメッセージの入力も省略されてコミットまで自動で行われます)
- A2: ただし、マージ中にコンフリクトした場合は、コンフリクトを解消して git add してから、自分で git commit する必要があります。
- Q: git merge --squash は?
- A1: すみませんハショりました>< 例えば git merge --squash topic は、topic ブランチ上のコミットを1つにまとめて (squash して)、1つのコミットとしてマージする事ができます。
- A2: Git には派閥がいろいろあって、merge --squash 派も一大派閥です。メリットとして、topic ブランチ側の変更が1つのコミットにまとまって見やすいし、取り消しやすい。マージ後の master のログが squash なマージコミットだけになって読みやすい、などがあります。
- Q: で、結局 merge なの? rebase なの?
- A: 残念ながら一概にどちらがベストとは言えません>< ただ、書いた通り rebase じゃなくて merge で済む場面がほとんどです。最後のまとめページ (P180) に書いた通り、明確な意図/目的を持って rebase するのは全然アリだと思います。
スライドの作り方について
ありがたいことに、色々な方に「どう作ったの?」「フォントは何?」と聞かれるので書いておきます。
まず、バイブルとして、 @riywo さんの下記のエントリを参考にさせて頂きました。ありがとうございます!
かっこいいスライドの作り方 #yapcasia 2012編 - As a Futurist...
使ってるのは Keynote です。
フォント
怖くない雰囲気をだしたかったので、まずは、ゆるふわな日本語フォントを探しました。
英語の git コマンドがたくさん出てくるので、英語フォントも吟味。Google Web Fonts で探しました。
- Bree Serif
- タイトルやちょっと目立たせたいところに使わせていただきました。
- Sansita One
- Question, Point など統一感が必要なタイトルに使わせていただきました。
- Strait
- git のコマンドをクールに見せたいところに使わせていただきました。
無意味に文字を大きくすると、なぜかカッコよく見えますw
ただし、テンポが重要なコミットグラフの変形などでは、あんまりコロコロとフォントサイズを変えないようにしています。
色
COLOURlovers で探しつつ、細かい部分については自分で微調整しました。
意識したのは
- 場面が切り替わるところではベース色も変える
- 警告や危ないところには赤系を使う
- 同じものには同じ色を使う (master, topic のブランチとコミットなど)
- コミットグラフが登場するような意識集中が必要なページは暗色系をメインに
- ただし、マンネリが続かないように、適度に刺激 (明るい色) を入れる
あとは、ポチポチと色を選んでいく、という感じです。
図
コミットグラフは、地道に Keynote の図形で丸や矢印をポチポチと置いていきました><
Keynote では、オブジェクトの整列が自然にできるようになってるのが便利でした。(Illustrator などのように、オブジェクトを移動していると中心軸などで吸着する)
図を作る上で心がけたのは
- 同じものには同じ形を使う
- 色と同じで、コミットなら丸、パッチなら四角、という風に形を統一しています。
- 情報量が増えるので、細かい説明を書かなくても伝わる、というメリットがあります。
- コミットグラフの変形や、重要な流れについては、なるべく丁寧に1ステップずつ作る
- おかげでページ数は増えてしまいましたが、「ここがこうだから」→「こうなる」という流れを切らないようにしました。
途中で登場する「犬」や「Git のロゴ」以外に、特に画像は使ってません。
説明・内容
説明を作るにあたって、気をつけていたのは以下のようなことです。
- なるべく、聴衆が考える事を予想して先回り先回りしていく
- 例えば、Fast-Forward でのブランチの移動など、聴衆が予想していない変化には「!?」とキャプションを入れて、「あなたの驚きは間違っていないよ」というのを伝えます。
- 予想するのは難しいですが、効果は高いと思います。
- 時々、主観を変えてみる
- 例えば、犬のキャラクタを入れて「なんだっけ?」「こうじゃないの?」と、聴衆の声を代理してみたり、Git 初心者のよくある勘違いを入れてみたり。
- 主観が変わると、場面転換を兼ねる事ができます。
- ほかにも、マージ中に「Git の中の人」などの擬人化人格を出して、「Git はこう考えている」というのがざっくりわかるようにするなど、説明の補助にも使えます。
- 少し笑いを入れてみる
- 社内向けの軽いノリの場という事もあり、結構ネタが入ってます。
- あまりやりすぎるとクドくなるのですが、それだけ力があるという事でもあり、印象に残りやすいと思います。
とはいえ
いろいろ書いてみたものの、別に上のことを計算して作ったわけではなくて、「わかりやすく伝える」事を目的にしたら、無意識に自分の中でルールが形成されていった感じです。
参考になれば幸いです><
Git ブランチから自動的に Jenkins ジョブを作る
Jenkins の Git プラグインは標準で複数ブランチのビルドに対応してるんですが、1つのジョブで全部のブランチをビルドするので
[成功 (master)] → [失敗 (branchA)] → [成功 (master)] → [失敗 (branchA)]
みたいな感じでブランチごとの成功/失敗がわかりづらく、IRC に通知出してると
FAILED! → Yippie! → FAILED! → Yippie! …
とうるさい感じで残念です。
というわけで軽くググったところ、引っかかった↓を導入します。
Jenkins "Build Per Branch" by entagen
インストール
まずはドキュメントに書かれている通り、Jenkins にプラグインをいくつかインストール。
- Git Plugin - Jenkins - Jenkins Wiki
- Gradle Plugin - Jenkins - Jenkins Wiki
- Nested View Plugin - Jenkins - Jenkins Wiki
あと、Jenkins のユーザーから Git リポジトリにアクセスできるように設定しておきました。
テンプレートジョブ作成
次に、自動生成されるジョブのテンプレートとなるジョブを作っておきます。通常は master に対してテストを実行するジョブになると思います。
- プロジェクト名: myproj
- テンプレートジョブの対象ブランチ: master
の場合、テンプレートジョブ名は以下のようにする必要があります。
myproj-<好きな名前>-master
僕の場合はテスト実行したいだけなので "myproj-test-master" みたいな感じにしました。
なお、<好きな名前> 部分を変えて複数のジョブを作れば、各ブランチに対して同じように複数のジョブが作られます。
テンプレートジョブは、コピーしてもすぐに動かせるように、ビルドを完全に自動化しておく必要があります。
また、ジョブの設定で [ソースコード管理システム] → [Git] → [Branches to build] を master にしておきます。
ブランチを同期させるジョブを作る
適当な名前(例: sync-myproj-branches)で「フリースタイル・プロジェクトのビルド」のジョブを作ります。*1
ジョブの設定は以下のようにしていきます。
ソースコード管理システム
- [Git] を選択
- [Repositories] の [Repository URL] に下記を入力
https://github.com/entagen/jenkins-build-per-branch.git
- [Branches to build] の [Branch Specified] に下記を入力
origin/master
ビルド・トリガ
[定期的に実行] を使ってもいいですが、僕の場合はフックで動かすようにしたので何もチェックを入れてません。
ビルド
[ビルド手順の追加] を押して [Invoke Gradle script] を選択します。
- [Use Gradle Wrapper] にチェックを入れます。
- [Switches] には、以下のオプションを指定する必要があります。
| オプション名 | 説明 | 例 |
|---|---|---|
| -DjenkinsUrl | Jenkins の URL | http://localhost:8080/jenkins |
| -DgitUrl | Git リポジトリの URL | git@github.com:example/repos.git |
| -DtemplateJobPrefix | 先ほど作ったテンプレートジョブのプロジェクト名部分 (上記の例なら myproj) |
myproj |
| -DtemplateBranchName | テンプレートジョブの対象ブランチ名 (上記の例なら master) |
master |
| -DnestedView | Jenkins トップのジョブ一覧でのグループ名(不要なら省略) | myproj-branches |
| -DdryRun | true を指定すると、実際には何も行わずに操作内容を見られる | true |
- 例として、[Switches] 入力欄の右側の [▼] を押して複数行入力にしてから、以下のように入力します。
-DjenkinsUrl=http://localhost:8080/jenkins -DgitUrl=git@github.com:example/repos.git -DtemplateJobPrefix=myproj -DtemplateBranchName=master -DnestedView=myproj-branches -DdryRun=true
- [Tasks] に下記を入力します。
syncWithRepo
実行
-DdryRun=true の状態で、先ほど作ったブランチを同期させるジョブ (sync-myproj-branches) をビルド実行します。
初回実行時は Gradle による依存ライブラリのインストールが走るので多少時間がかかります。
ビルド結果のコンソール出力から、どのような操作が行われるか確認できます。
問題なければ、ジョブ設定の [Switches] から "-DdryRun=true" の行を削除すれば、実際にジョブが作成されます。
これで、Git ブランチとジョブの同期ができるようになりました。
フックで実行
次に、Git リポジトリに何かがプッシュされたら、自動的にブランチとジョブを同期してから、変更されたブランチのジョブをビルド実行するようにしたいです。
まず、Git のサーバーサイドフックや、Git フロントエンドの WebHook 機能などで、プッシュがあったタイミングで下記の URL に POST するようにします。(sync-myproj-branches は自分のジョブ名に書き換えて下さい)
http://<JenkinsのURL>/job/sync-myproj-branches/build
僕の場合は、GitLab を使ってたので、プロジェクトの Hooks から上記の URL を追加しておくだけで OK でした。
ジョブとブランチの同期後にビルド実行
これで、Git に何かがプッシュされる度に自動的にブランチとジョブが同期されるようになりましたが、これだけでは同期で作られたジョブのビルドが実行されませんので、ブランチ同期ジョブ (sync-myproj-branches) のビルド手順に以下を追加しました。
- [ビルド手順の追加] → [シェルの実行] を選択
- シェルスクリプト欄に下記を入力
curl -s "http://<JenkinsのURL>/git/notifyCommit?url=<GitリポジトリのURL>"
これで、同期が終わったタイミングで Git プラグインに通知され、更新されたブランチに関連するジョブでビルドが実行されるようになりました。
やったー\(^o^)/
*1:ドキュメントでは「SyncYOURPROJECTGitBranchesWithJenkins」という名前で作れと書いてありますが、好きな名前で動かせます